
Here’s a Plain C/C++ Implementation of AI Speech Recognition, So Get Hackin’
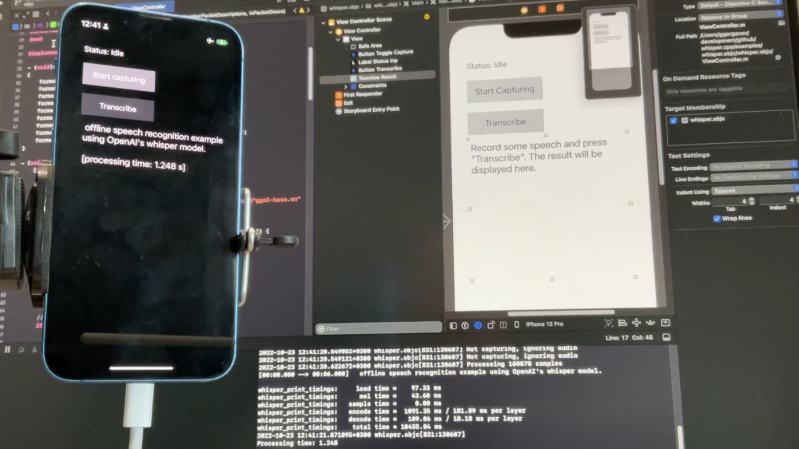
[Georgi Gerganov] recently shared a great resource for running high-quality AI-driven speech recognition in a plain C/C++ implementation on a variety of platforms. The automatic speech recognition (ASR) model is fully implemented using only two source files and requires no dependencies. As a result, the high-quality speech recognition doesn’t involve calling remote APIs, and can run locally on different devices in a fairly straightforward manner. The image above shows it running locally on an iPhone 13, but it can do more than that.
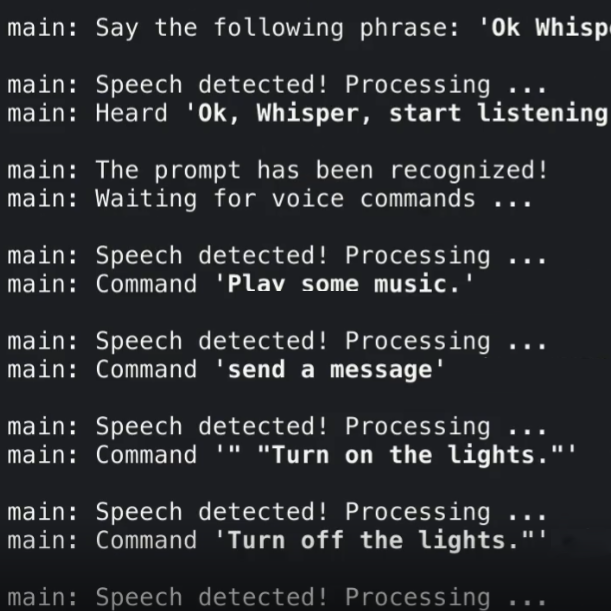
The usual way that OpenAI’s Whisper works is to feed it an audio file, and it spits out a transcription. But [Georgi] shows off something else that might start giving hackers ideas: a simple real-time audio input example.
By using a tool to stream audio and feed it to the system every half-second, one can obtain pretty good (sort of) real-time results! This of course isn’t an ideal method, but the robustness and accuracy of Whisper is such that the results look pretty great nevertheless.
You can watch a quick demo of that in the video just under the page break. If it gives you some ideas, head over to the project’s GitHub repository and get hackin’!




Post a Comment