
Data Alignment Across Architectures: The Good, The Bad And The Ugly

Even though a computer’s memory map looks pretty smooth and very much byte-addressable at first glance, the same memory on a hardware level is a lot more bumpy. An essential term a developer may come across in this context is data alignment, which refers to how the hardware accesses the system’s random access memory (RAM). This and others are properties of the RAM and memory bus implementation of the system, with a variety of implications for software developers.
For a 32-bit memory bus, the optimal access type for some data would be a four bytes, aligned exactly on a four-byte border within memory. What happens when unaligned access is attempted – such as reading said four-byte value aligned halfway into a word – is implementation defined. Some hardware platforms have hardware support for unaligned access, others throw an exception that the operating system (OS) can catch and fallback to an unaligned routine in software. Other platforms will generally throw a bus error (SIGBUS in POSIX) if you attempt unaligned access.
Yet even if unaligned memory access is allowed, what is the true performance impact?
A Hardware View
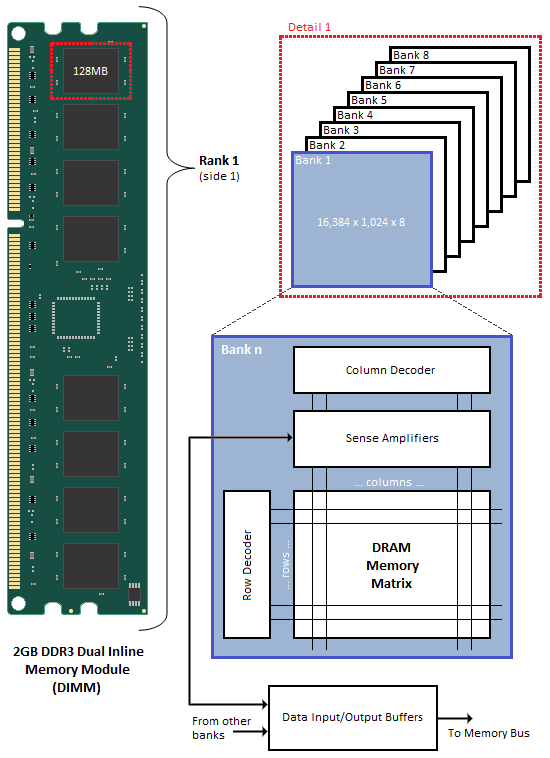
For as nebulous as system memory may seem, its implementation in the form of synchronous dynamic random-access memory (SDRAM) is very much bound to physical limitations. A great primer to how SDRAM works is found in a 2010 Anandtech article by Rajinder Gill. The essential take-away from this is how the SDRAM modules are addressed.
Each read and write request has to select the target bank on a DIMM (BAn), followed by commands that specify the target row (RAS) and column (CAS). Each row consists out of many thousands of cells, with each SDRAM chip on a DIMM contributing eight bits to the 64-bit data bus found on DDR 3 and DDR 4 DIMMs.
The consequence of this physical configuration is that all access to RAM and intermediate cache(s) is aligned along these physically defined borders. When a memory controller is tasked to retrieve the data for some variable, it is incredibly helpful when this data can be fetched from RAM in a single read operation so that it can be read into a register of the CPU.
What happens when this data is not aligned? It’s possible to read first the initial section of data, then perform a second read to obtain the final section, and then merge the two parts. Naturally, this is an operation that has to be either supported by the memory controller directly, or handled by the operating system.
The memory controller will generate a bus error when it is asked to access an invalid address, stumbles across a paging error, or is asked to perform unaligned access when this is unsupported. Platforms such as x86 and derivatives do support unaligned memory access.
When Things Explode
As noted, x86 and also x86_64 are essentially just fine with however you access system RAM with whatever alignment you picked or randomly ended up using. Where things get messier is with other platforms, such as ARM, with the ARMv7 documentation listing the properties of the platform in the context of unaligned data access. Essentially, in quite a few cases you will get an alignment fault from the hardware.
In this IBM article from 2005, it is covered how the Motorola m68k, MIPS and PowerPC CPUs of that era handled unaligned access. The interesting thing to note here is that until the 68020, unaligned access would always throw a bus error. MIPS CPUs didn’t bother with unaligned access in the name of speed, and PowerPC took a hybrid approach, with 32-bit unaligned access allowed, but 64-bit (floating point) unaligned access resulting a bus error.
When it comes to replicating the SIGBUS alignment error, this is easily done using e.g. the dereferencing of a pointer:
uint8_t* data = binary_blob; uint32_t val = *((uint32_t*) data);
Here binary_blob is assumed to be a collection of variable-sized values, not just 32-bit integers.
While this code will run fine on any x86 platform, on an ARM-based platform such as the Raspberry Pi, dereferencing in this manner is pretty much guaranteed to get you a SIGBUS fault and a very dead process. The problem is namely that when you request to access the uint8_t pointer as a 32-bit integer, the chances of this being a properly aligned uint32_t are essentially zero.
So what is one to do in this case?
Staying Aligned
Arguments for using aligned memory access are many. Some of the most important ones are atomicity and portability. Atomicity refers to an integer read or write that can be performed in a single read or write operation. In the case of unaligned access, this atomicity no longer applies because it has to read across boundaries. Some code may rely on such atomic reads and writes, which when unaligned access is not taken into account may lead to interesting and sporadic bugs and crashes.
The very obvious elephant in the room, however, is that of portability. As we saw in the preceding section, it is very easy to write code that works great on one platform, but will die pitifully on another platform. There is however a way to write code that will be fully portable, which is in fact defined within the C specification as the one true way to copy data without running into alignment issues: memcpy.
If we were to rewrite the earlier code fragment using memcpy, we end up with the following code:
#include <cstring> uint8_t* data = binary_blob; uint32_t val; memcpy(&val, data, 4);
This code is fully portable, with the memcpy implementation handling any alignment issues. If we execute code like this on e.g. a Raspberry Pi system, no SIGBUS fault will be generated, and the process will live on to see another CPU cycle.
Data structures, struct in C, are groupings of related data values. As these are to be placed in RAM in a consecutive manner, this would obviously create alignment issues, unless padding is applied. Compilers add such padding where necessary by default, which ensures that each data member of a struct is aligned in memory. Obviously this ‘wastes’ some memory and increases the size of the structure, but ensures that every access of a data member occurs fully aligned.
For common cases where structs are used, such as memory-mapped I/O on MCUs and peripheral hardware devices, this is generally not a concern as these use only 32-bit or 64-bit registers that are always aligned when the first data member is. Manually tweaking structure padding is often possible with compiler toolchains for performance and size reasons, but should only be done with the utmost care.
Performance Impact
But, one may ask, what is the performance impact of ignoring data alignment and just letting the hardware or the OS cover up the complications? As we saw in the exploration of the physical implementation of system RAM, unaligned access is possible, at the cost of additional read or write cycles. Obviously, this would at least double the number of such cycles. If this were to occur across banks, the performance impact could be major.
In the earlier referenced 2005 IBM article by Johnathan Rentzsch, a number of benchmark results are provided using single, double, four and eight-byte access patterns. Despite running on a rather sluggish 800 MHz PowerBook G5, the impact of unaligned access was quite noticeable, with two-byte unaligned access being 27% slower than aligned access. For four-byte unaligned access, this was slower than aligned two-byte access, rendering the switch to larger data sizes irrelevant.
When switching to eight-byte aligned access, this was 10% faster than aligned four-byte access. Yet unaligned eight-byte access took an astounding 1.8 seconds for the whole buffer, 4.6 times slower than aligned, on account of the PowerPC G4 not having hardware support for eight-byte unaligned access, with the OS instead performing the requisite merging operations.
The performance impact does not just concern standard CPU ALU operations, but also SIMD (vector) extensions, as detailed by Mesa et al. (2007). Additionally, during development of the x264 codec it was found that using cacheline alignment (aligned 16-byte transfer) was 69% faster on one of the most commonly used functions in x264. The implication here being that data alignment goes far beyond system RAM, but also applies to caches and other elements of a computer system.
Much of this comes down to the doubling of (common) operations and the resulting hit to overall performance.
Wrap-up
In some ways the x86 architecture is rather comfortable in how it shields you from the ugly parts of reality, such as unaligned memory access, but reality has a way of sneaking up on you when you least expect it. One such occasion occurred for me a few months ago while doing some profiling and optimizations on a remote procedure call library.
After the Cachegrind profiling tool in Valgrind had shown me the excessive amount of unaligned copying going on in the internals, the challenge was to not only implement a zero-copy version of the library, but also in-place parsing of binary data. Which led to some of the aforementioned implications with unaligned memory access upon dereferencing of the (packed) binary data.
Although the issue was easily solved using the aforementioned memcpy-based solution, it provided me with a fascinating look at SIGBUS faults on ARM-based systems where the same code had worked without a hitch on x86_64 systems. As for the performance impact? The benchmarks before and after the modifications to the RPC library showed a remarkable increase in performance, which may in part have been due to the switch to aligned access.
Even though there are people around who insist that the performance hit from unaligned access is not significant enough today to worry about, the very real impact on portability and atomicity should give anyone pause. Beyond that, it is totally worth it to run the code through a profiler to get a feel for what the memory access patterns are like, and what could be improved or optimized.





Post a Comment